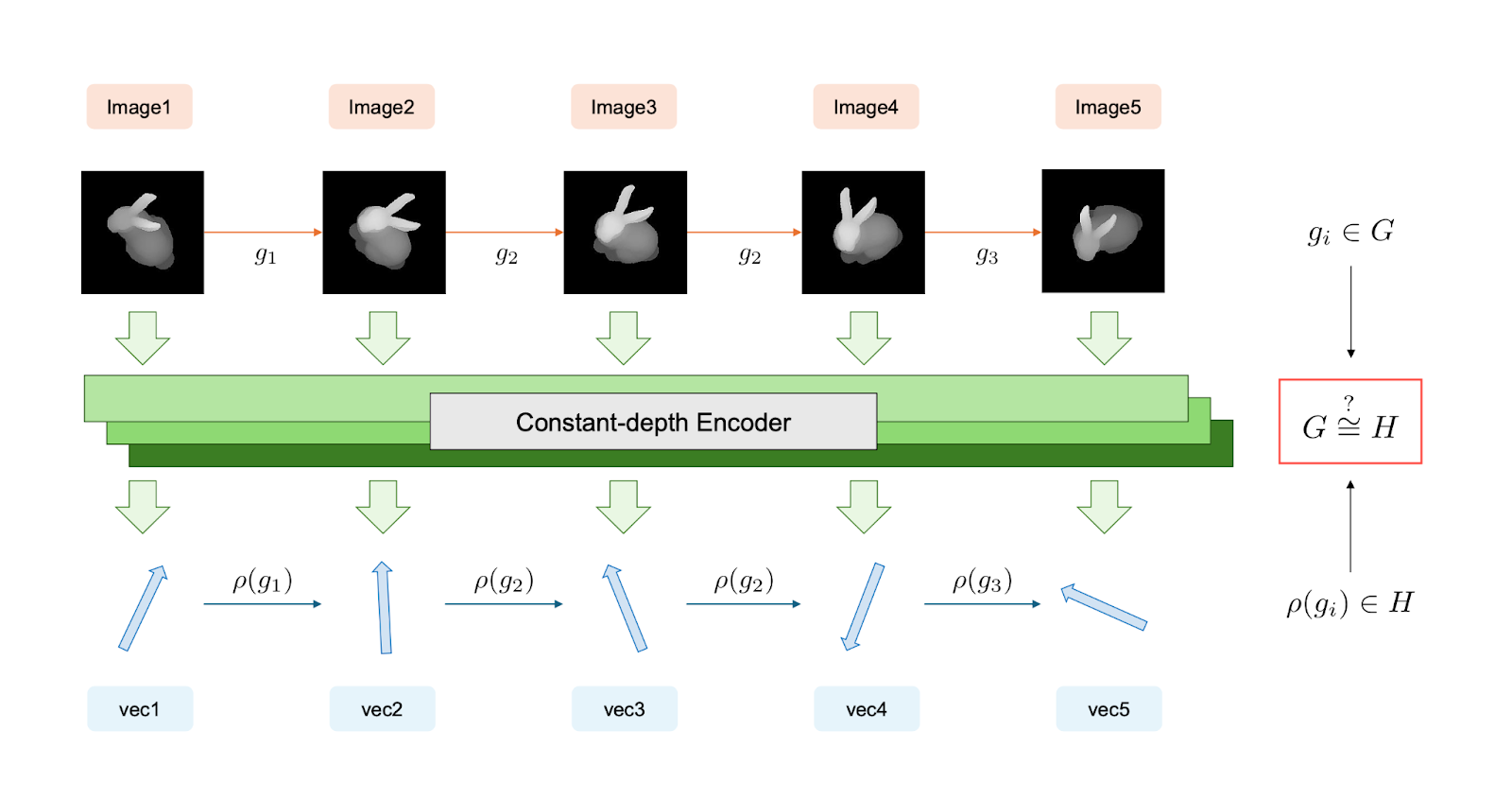
On a Monday in January, three researchers in Nanjing posted a paper with a rotating bunny on the first page. The bunny spins through five frames, ears tilting, body turning. Below it, a green bar labeled "Constant-depth Encoder." Below that, vectors. The question in red: does the math inside match the motion outside?
The answer is no. And the paper proves it can't.
Vision Transformers see the world as patches. Chop an image into 16×16 grids, embed each patch as a token, let attention flow between them. The architecture dominates computer vision. Classification, segmentation, multimodal alignment. Name a benchmark, a ViT probably tops it.
But there's a pattern in the failures. Ask a model whether an object is left or right of another. Show it a shape, rotate it, ask if it's the same shape or its mirror. Tasks that feel trivial. Tasks four-year-olds do without thinking.
The models fail. Not occasionally. Systematically.
The standard explanation: not enough data. Not enough scale. Train longer, train bigger, the failures will smooth out.
Siyi Lyu, Quan Liu, and Feng Yan asked a different question. What if the architecture itself is the ceiling?
To understand their answer, you need a detour through complexity theory. Not the hand-wavy kind. The kind with proofs.
Computational problems fall into classes based on the resources required to solve them. Two classes matter here: TC⁰ and NC¹.
TC⁰ is the class of problems solvable by constant-depth circuits with threshold gates. Massive parallelism, shallow depth. Width scales polynomially with input size, but the number of sequential steps stays fixed.
NC¹ requires logarithmic depth. Still parallel, but the circuit can grow deeper as the input grows. Problems in NC¹ can chain dependencies. Step two depends on step one. Step three depends on step two. The depth scales with the problem.

The conjecture TC⁰ ⊊ NC¹ says these classes are different. Constant-depth circuits cannot simulate logarithmic-depth circuits, no matter how wide you make them. The conjecture is unproven, but the consensus is P ≠ NP level. If it's wrong, most of what we think we know about computation is wrong.
Here's the connection. Standard Vision Transformers, operating with fixed layers and polynomial precision, are bounded by TC⁰. Recent theoretical work has locked this down. Transformers excel at parallel pattern matching. They struggle with anything requiring sequential composition.
The Nanjing team formalized spatial understanding as a group homomorphism problem.
A group is a set of transformations with a composition rule. Rotate 30 degrees, then rotate 45 degrees, and you get a rotation of 75 degrees. The composition has structure. It follows laws.
For a model to truly understand spatial transformation, its internal representation must preserve that structure. If you rotate an object twice, the model's latent space should reflect two rotations composed. This is what the paper calls a Homomorphic Spatial Embedding.
The question becomes: can a constant-depth encoder maintain this structure?
For simple transformations, yes. 2D translations are abelian. Order doesn't matter. Translate left then up, or up then left. Same result. TC⁰ circuits can handle abelian structure.
But 3D rotation is different. The rotation group SO(3) is non-solvable. It contains subgroups where the Word Problem is NC¹-complete. To track a sequence of 3D rotations, you need logarithmic depth. You need to chain dependencies.
Under the conjecture TC⁰ ⊊ NC¹, constant-depth transformers cannot do this. Not "struggle with." Cannot. The architecture lacks the logical depth to preserve the algebra.
The team tested it.
They built a benchmark called Latent Space Algebra. Three levels of difficulty, matched for visual complexity but separated by algebraic structure.
Level 1: 2D translation. Abelian. Move an object around a grid.
Level 2: Affine transformations. Scaling plus translation. Non-commutative but solvable. The group can be decomposed into abelian pieces.
Level 3: 3D rotation. Non-solvable. The theoretical barrier.
They tested ViT-B/16 (supervised on ImageNet), DINOv2 (self-supervised, explicitly trained to preserve geometry), and ResNet-50. Frozen weights. Linear probes trained only on single-step transitions, then tested on sequences of 2 to 20 steps.
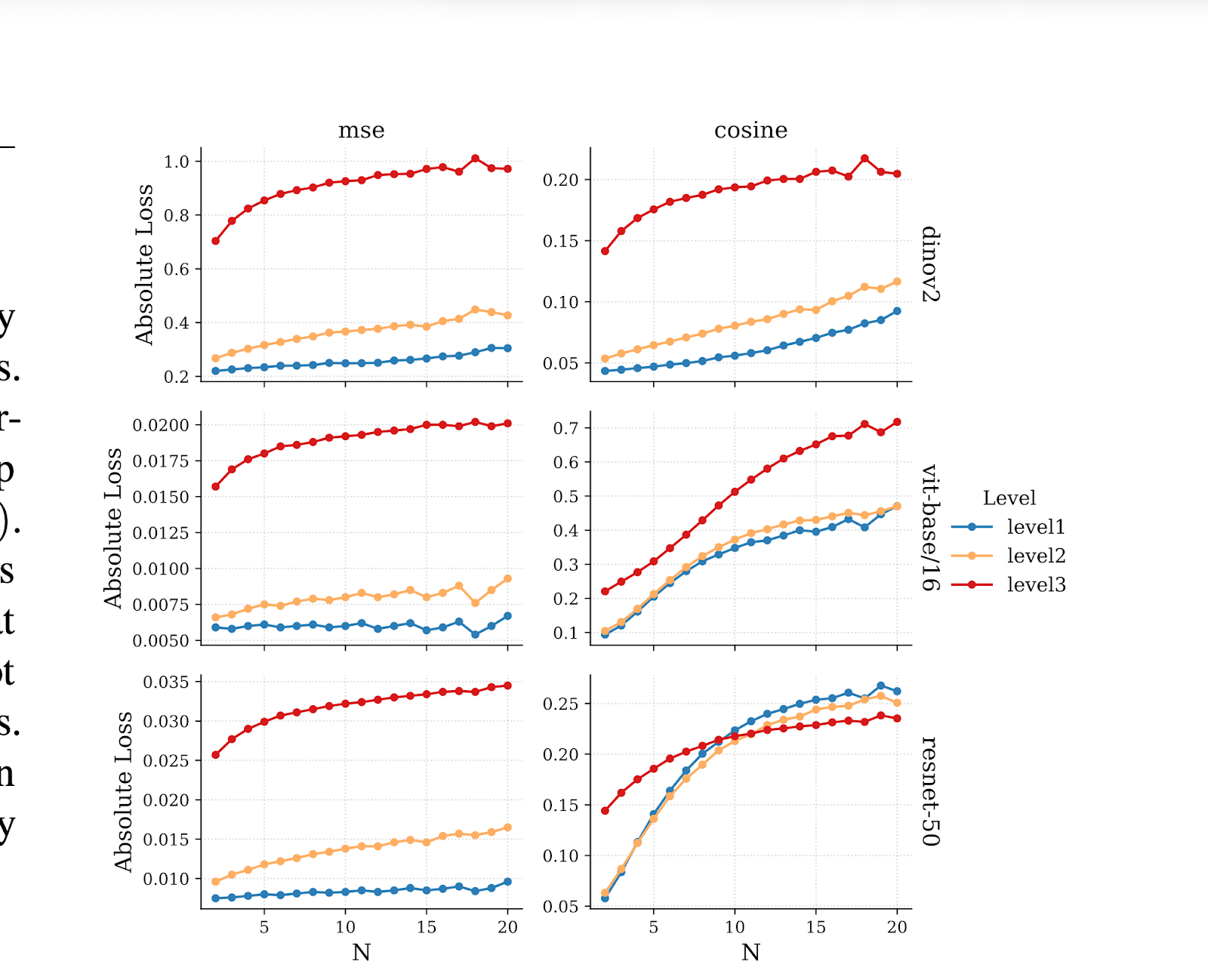
The results were stark.
On Level 1, errors grew slowly. The models could track translations over extended sequences.
On Level 3, errors compounded. By sequence length 9 or 10, the models performed worse than a baseline that simply guessed the object hadn't moved. Prediction collapsed.
The gap between Level 1 and Level 3 was 3× to 3.8× in absolute error. Not a gradual degradation. A structural break.
The DINOv2 result matters most.
DINOv2 is trained without labels. Its objective encourages geometric sensitivity. If any vision model should preserve spatial structure, it's this one.
It still failed on SO(3). The errors compounded at the same rate. The architectural ceiling held.
This rules out the training objective as the bottleneck. Supervised models failed partly because classification encourages invariance to translation and rotation. But DINOv2 doesn't have that excuse. It was trained to care about geometry.
The constant-depth circuit is the ceiling. Not the loss function. Not the data. The architecture.
I emailed the corresponding author, Feng Yan, with three questions. He responded within a day, co-signed by first author Siyi Lyu.
On the TC⁰/NC¹ conjecture:
"The separation between TC⁰ and NC¹ is widely accepted in the theoretical community. While the consensus level is indeed similar to that of P ≠ NP, the implications differ. This relationship fundamentally addresses whether there is a distinction between 'parallel' and 'serial' computation. If TC⁰ = NC¹, it would imply that very shallow neural networks could perform tasks that strictly require deep processing. This would fundamentally overturn our current understanding of neural network architectures."
On real-world failure modes:
"As the sequence of spatial group operations increases, the predictions of a network restricted to the TC⁰ complexity class will gradually drift. In autonomous driving, this manifests as risks in complex terrains involving intricate 3D relationships and during long-duration driving. We predict that current methods may produce significant deviations."
On the path forward:
"This remains largely an open problem. Fixed-depth architectures struggle with long-sequence 3D spatial reasoning. However, simply increasing depth reintroduces historical challenges like training difficulties and error accumulation. Adding hard-coded inductive biases hampers generality. Hybrid architectures or new geometric modules might be the solution."
This paper doesn't stand alone.
A body of work is converging on the same conclusion through different angles. "The Illusion of State in State-Space Models" proves that SSMs, despite their recurrent formulation, hit the same TC⁰ ceiling as transformers. The "state" is an illusion. Mamba doesn't escape the barrier.
"Circuit Complexity Bounds for RoPE-based Transformer Architecture" shows that rotary position embeddings don't help. RoPE transformers with constant depth still can't evaluate Boolean formulas.
"A Little Depth Goes a Long Way" demonstrates the positive case. Log-depth transformers can express sequential reasoning impossible for fixed-depth models. Depth is the lever, not width, not chain-of-thought.
The empirical failures follow the theory. LLMs struggle with parenthesis matching. Determining whether a sequence like (((())(())))((()) is balanced requires tracking nested state. NC¹ territory. Models fumble it.
Knot untying is another test case. The KnotGym benchmark shows that model-based RL and chain-of-thought reasoning both fail at rope manipulation as complexity increases. Spatial reasoning that humans do without thinking.
The dilemma has no clean exit.
Fixed depth can't solve non-solvable group structures. The proof is there.
Adding depth brings back the problems transformers were designed to escape. RNNs could chain dependencies, but they were unstable over long sequences. Vanishing gradients. Exploding gradients. Training pathologies that made them impractical at scale.
Hard-coding geometric structure, like SE(3)-equivariant networks, embeds the algebra into the architecture. But the non-solvable structure lives in fixed coefficients. The learnable dynamics remain bounded. And you lose generality. You can't "automatically learn" spatial relationships if you've pre-specified the geometry.
The authors acknowledge this openly:
"Biological spatial perception differs significantly from our current paradigms. Humans perceive object constancy and handle knots and occlusions without complex, conscious reasoning. Continued cross-disciplinary thinking is essential."
A four-year-old watches a toy rotate and knows it's the same toy. No computation. No conscious tracking of axes and angles. The perception is immediate.
We don't know how that works. We don't know how to build it.
What we do know, now, is that the architectures dominating computer vision cannot learn it. The ceiling isn't data or training or scale. It's deeper than that.
The bunny keeps spinning. The models keep failing. The question of how to build systems that actually understand space remains open.
Sources
- Lyu, Liu, Yan. "On the Intrinsic Limits of Transformer Image Embeddings in Non-Solvable Spatial Reasoning." arXiv:2601.03048. January 2026.
- Author correspondence. January 9, 2026.
- Merrill et al. "The Illusion of State in State-Space Models." arXiv:2404.08819.
- Chen et al. "Circuit Complexity Bounds for RoPE-based Transformer Architecture." arXiv:2411.07602.
- "A Little Depth Goes a Long Way: The Expressive Power of Log-Depth Transformers." arXiv:2503.03961.
- "Knot So Simple: A Minimalistic Environment for Spatial Reasoning." arXiv:2505.18028.
Credibility Assessment Assisted by Claude Opus 4.5
Paper: On the Intrinsic Limits of Transformer Image Embeddings in Non-Solvable Spatial Reasoning
Authors: Siyi Lyu, Quan Liu, Feng Yan (School of Electronic Science and Engineering, Nanjing University)
Status: Preprint at arXiv (2601.03048), submitted January 6, 2026
Author Verification ⚠ Limited independent verification possible. "Feng Yan" at Nanjing University's School of Electronic Sciences appears in one recent publication (cell segmentation, Chemical & Biomedical Imaging), but "Siyi Lyu" and "Quan Liu" at this specific institution could not be independently verified through Google Scholar or faculty pages.
Institution Check ✓ Nanjing University is a legitimate top-tier Chinese research institution (C9 League). The School of Electronic Science and Engineering is a real department with active research programs.
Citation Sampling ✓ Key theoretical citations verified: Barrington (1986) on NC¹-completeness of word problems for non-solvable groups is a foundational result; Merrill & Sabharwal (2023) "Parallelism Tradeoff" paper establishing TC⁰ bounds for transformers exists in TACL and arXiv. Chiang (2025) "Transformers in uniform TC⁰" also confirmed.
Methodology Specificity ✓ Highly specific methodology: fixed action space |Σ|=6, atomic angle θ=30°, sequence lengths N=1-20, batch size 1024, learning rate 1×10⁻⁴, 50 epochs, explicit Algorithm 1 for recursive linear probing, specific model architectures (ViT-B/16, DINOv2 ViT-B/14, ResNet-50). Stanford 3D Scanning Repository confirmed as legitimate source for test objects.
Limitations Disclosed ✓ Authors explicitly acknowledge: (1) the result is conditional on TC⁰⊊NC¹ conjecture, (2) chain-of-thought unrolling could theoretically bypass limits but faces analog stability issues, (3) code availability is "anonymous GitHub link" pending publication. The boundary analysis section directly addresses potential counterarguments.
Code/Data Availability ⚠ Paper claims "anonymous GitHub link" for code, which is standard for anonymous review but currently unverifiable. No DOI or permanent repository link provided.
Peer Review Status Preprint — Under review (implied by January 2026 date and "Preprint" watermark). No venue claimed.
Overall Assessment: PASS
This is a theoretically rigorous paper connecting circuit complexity bounds to practical failures in Vision Transformer spatial reasoning. The core argument—that constant-depth architectures bounded by TC⁰ cannot compute group homomorphisms for non-solvable groups (which are NC¹-complete via Barrington's theorem)—is mathematically sound and draws on well-established complexity theory. The experimental methodology uses standard benchmarks (Stanford 3D models) and widely-used architectures (ViT, DINOv2, ResNet).
The author verification flag is a minor concern—new researchers with limited online presence are normal, and Nanjing University is a legitimate institution. The anonymous code link is appropriate for anonymous review. The paper's explicit acknowledgment that its impossibility result is conditional on a widely-believed but unproven complexity separation (TC⁰⊊NC¹) demonstrates appropriate epistemic humility rather than overclaiming.
This assessment evaluates credibility indicators, not absolute authenticity. Reader discretion advised.